
Before You Scale: What Chapter 1 of Designing Data-Intensive Applications Actually Teaches You
Everyone cites Designing Data-Intensive Applications. It’s on the reading list of every serious engineering team. Engineers drop it in interviews. CTOs reference it in system design discussions. But most people read it once, nod along, and move on without internalizing what the first chapter is actually saying.
Chapter 1 isn’t an introduction. It’s a framework. And it’s one I keep coming back to every time I’m making architecture decisions for early-stage teams.
Here’s what I took from it — and why it matters beyond the code.
The bottleneck shifted. Did your thinking?
“CPU is no longer the limiting factor for most applications. The problems are now the amount of data, the complexity of data, and the speed at which it is changing.” — Martin Kleppmann, Designing Data-Intensive Applications
For most of computing history, performance was about raw computation. You needed a faster processor; you upgraded the hardware. That was the game.
That game changed. The bottleneck in most modern applications isn’t compute — it’s data. How much of it you have, how fast it arrives, how inconsistent it is across systems, and how hard it is to keep it correct while everything else keeps moving.
This reframes what good engineering means. You’re not optimizing an algorithm anymore. You’re designing how data flows, where it lives, how it transforms, and what happens when part of that pipeline breaks. The mental model of the “programmer who writes fast code” is increasingly less relevant than the mental model of the “engineer who designs resilient data systems.”
For founders building products today: if your bottleneck isn’t compute, optimizing for compute is wasted investment. The right question is where your data complexity actually lives.
You’re not building an app. You’re composing a system.
“There is unlikely to be one piece of software that is suitable for all the different circumstances in which the data needs to be used.” — Martin Kleppmann, Designing Data-Intensive Applications
Redis started as a cache. Teams started using it as a message queue. Kafka was built for event streaming — and now offers durability guarantees that rival traditional databases. The boundaries between tool categories dissolved years ago.
What this means in practice: every modern application is a composed system. You’re not choosing “the database” — you’re designing an architecture that combines a primary store, a caching layer, a search index, maybe a queue, maybe a stream processor. Each with different guarantees, different failure modes, different latency profiles.
The problem is that when you compose systems, no single tool’s documentation tells you how the whole thing behaves. That’s your responsibility. You become the architect of something that doesn’t exist in any spec — it emerges from the interactions between components you chose.
I’ve seen early-stage teams underestimate this repeatedly. They pick the right individual tools and then spend months debugging behaviors that only appear at the seams.
Reliability: design for faults, not against them
“A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.” — Leslie Lamport, Turing Award winner
Kleppmann makes a distinction that sounds academic but has real engineering consequences: the difference between a fault and a failure. A fault is a component deviating from its spec. A failure is the whole system stopping to provide its service. The goal of a reliable system is to prevent faults from becoming failures.
This is a subtle shift in how you design. You stop trying to prevent every possible fault (you can’t) and start designing so that faults are contained. A disk dying in a datacenter is a daily occurrence at scale — not an exceptional event to plan for. A node going down should be boring. The system should absorb it and continue.
Netflix’s Chaos Monkey — the tool that randomly kills production services — exists precisely because of this logic. If your system can’t survive a randomly killed process in controlled conditions, it certainly can’t survive real-world failures. Chaos engineering isn’t masochism. It’s the natural consequence of taking fault tolerance seriously.
For the teams I work with: the moment you go from a single server to anything distributed, fault tolerance stops being optional. You need to design for it from day one, not retrofit it when something breaks at 3am.
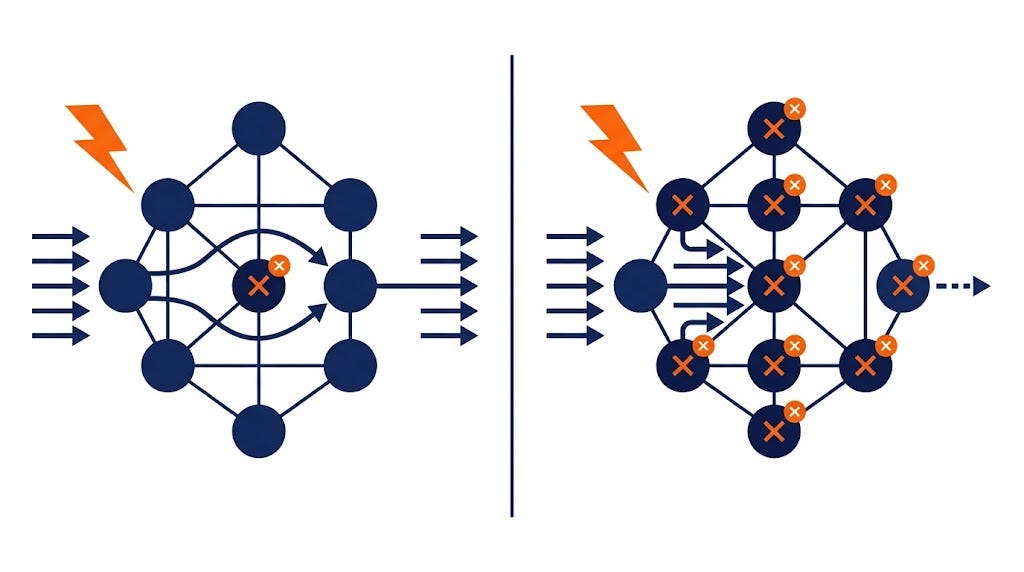
Human error causes more downtime than hardware. Design accordingly.
“Everything fails, all the time.” — Werner Vogels, CTO of Amazon
Configuration mistakes by engineers cause more production outages than disk failures or network partitions. Kleppmann is explicit about this, and it’s a point that tends to get skipped over in discussions about reliability — because it’s uncomfortable. We’d rather blame hardware.
The right response to human error isn’t “be more careful.” Careful doesn’t scale. The response is design that makes the wrong action hard to take and the right action obvious.
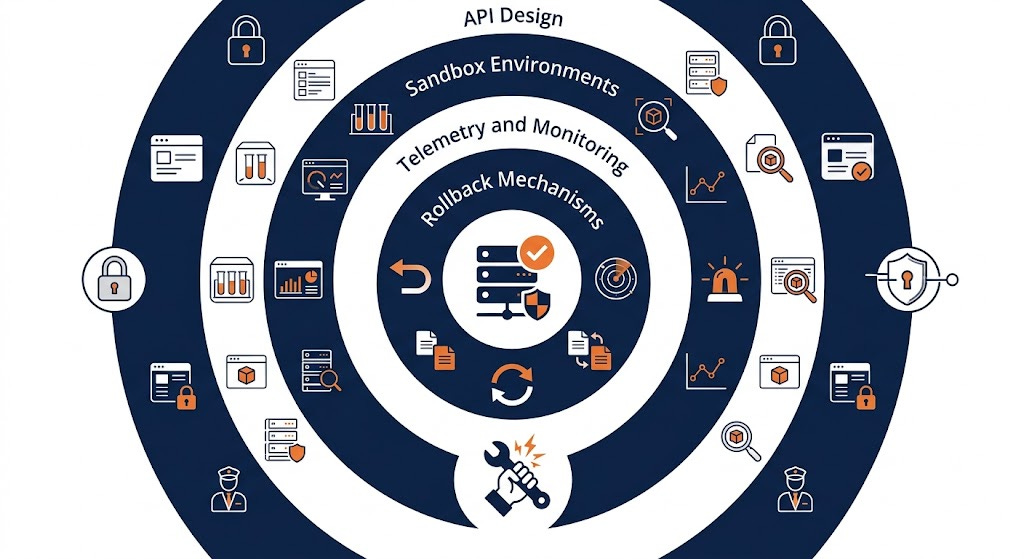
What that looks like in practice:
APIs that don’t expose footguns — if the interface allows you to shoot yourself, someone will
Sandboxed environments where engineers can test changes without touching production data
Telemetry that surfaces anomalies before users notice them
Rollback mechanisms that actually work, not ones that are theoretically possible
This has a direct implication for how you build internal tooling. Every time you design an internal API, a CLI command, or an admin panel, you’re making a choice about how much damage a tired engineer can accidentally cause at midnight.
Scalability is a question you answer per load parameter, not a feature you add
“Scalability is frequently used as a magic incantation to indicate that something is badly designed or broken.” — Werner Vogels, CTO of Amazon
“We need to make it scalable” is one of the most dangerous phrases in early-stage engineering. It usually means nothing specific, and it tends to lead to over-engineering that solves problems you don’t have while creating complexity you can’t afford.
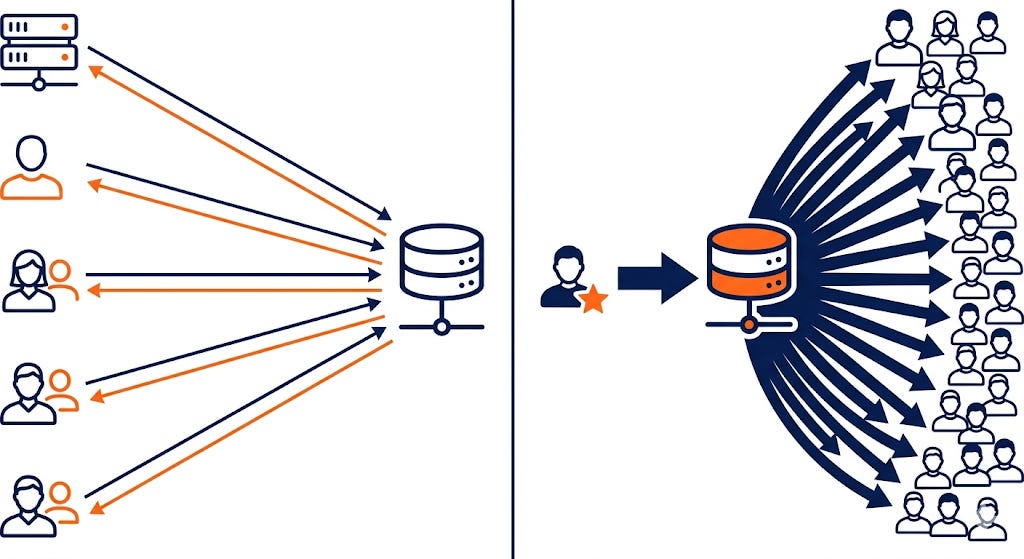
Kleppmann’s framing is cleaner: scalability is about describing your load parameters precisely, then understanding how your system behaves as those parameters increase. For Twitter, the core load parameter isn’t tweets-per-second — it’s the fan-out problem: one tweet from a celebrity with 30 million followers needs to land in 30 million home timelines. That’s a fundamentally different problem than just “more writes per second,” and it demands a different architectural approach.
The metrics question matters too. Average response time is almost useless as a performance metric. What you want is the 99th percentile — the experience of your slowest users. Those users are often your most engaged, highest-value customers. They have the most data, the most history, the most transactions. The mean hides exactly the cases that matter most.
Scale to your actual load parameters. Measure p99, not averages. Don’t add complexity for scale you don’t have yet — but understand where your real bottlenecks will be when you do.
Maintainability is where engineering ROI actually lives
“The complexity of software is an essential property, not an accidental one... descriptions of a software entity that abstract away its complexity often abstract away its essence.” — Fred Brooks, No Silver Bullet (1986)
Kleppmann breaks maintainability into three properties: operability (can your team run this system without heroics?), simplicity (can a new engineer understand it without a two-week onboarding?), and evolvability (can you change it when requirements change, without rewriting everything?).
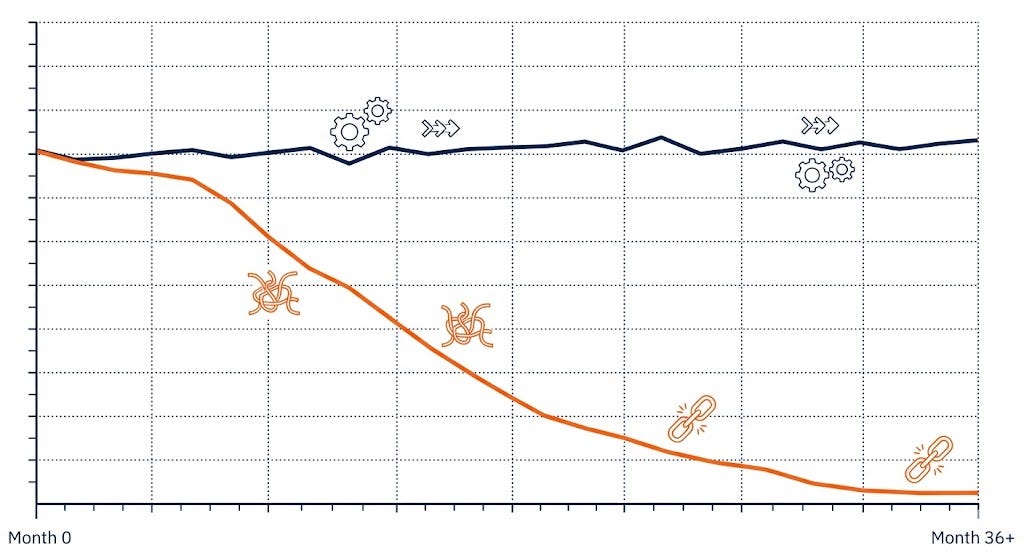
The enemy here is accidental complexity — the complexity that comes from implementation choices, not from the problem itself. Every shortcut that creates coupling. Every abstraction that leaks. Every clever optimization that only the person who wrote it understands. This complexity accumulates silently and compounds.
I’ve worked with teams where the engineering velocity at month 18 was a fraction of what it was at month 3 — not because the team got worse, but because the codebase had accumulated so much accidental complexity that every change required understanding the entire system. That’s the cost of not taking maintainability seriously from the start.
For founders: when you’re evaluating engineering quality, don’t just ask “does it work?” Ask “how hard is it to change?” A system that works but can’t evolve will become a liability exactly when your product needs to move fastest.
Reliability, Scalability, Maintainability. Kleppmann frames these as the three core concerns of any data system — and I’d extend that: they’re the three questions that determine whether your product survives its own success.
Most teams treat them as non-functional requirements to be addressed later. The ones that get it right treat them as design constraints from day one.
Read DDIA. But read chapter 1 twice.