
The AI Product Trap
Most AI products look great in a demo. The data is clean. The prompts have been tuned by someone who knows exactly what the model responds well to. The person running the demo knows which questions to ask — and which ones to avoid.
Then the product ships.
And real users arrive with questions nobody anticipated, inputs that are messy and incomplete, requests that combine things in ways that make no sense. The model that was performing so well three weeks ago in a controlled environment starts producing outputs that are wrong in ways that are hard to predict, harder to reproduce, and nearly impossible to explain to a client.
This is the AI product trap. It’s not a technical failure. It’s a failure of expectations — and most founders only see it after they’ve already committed.
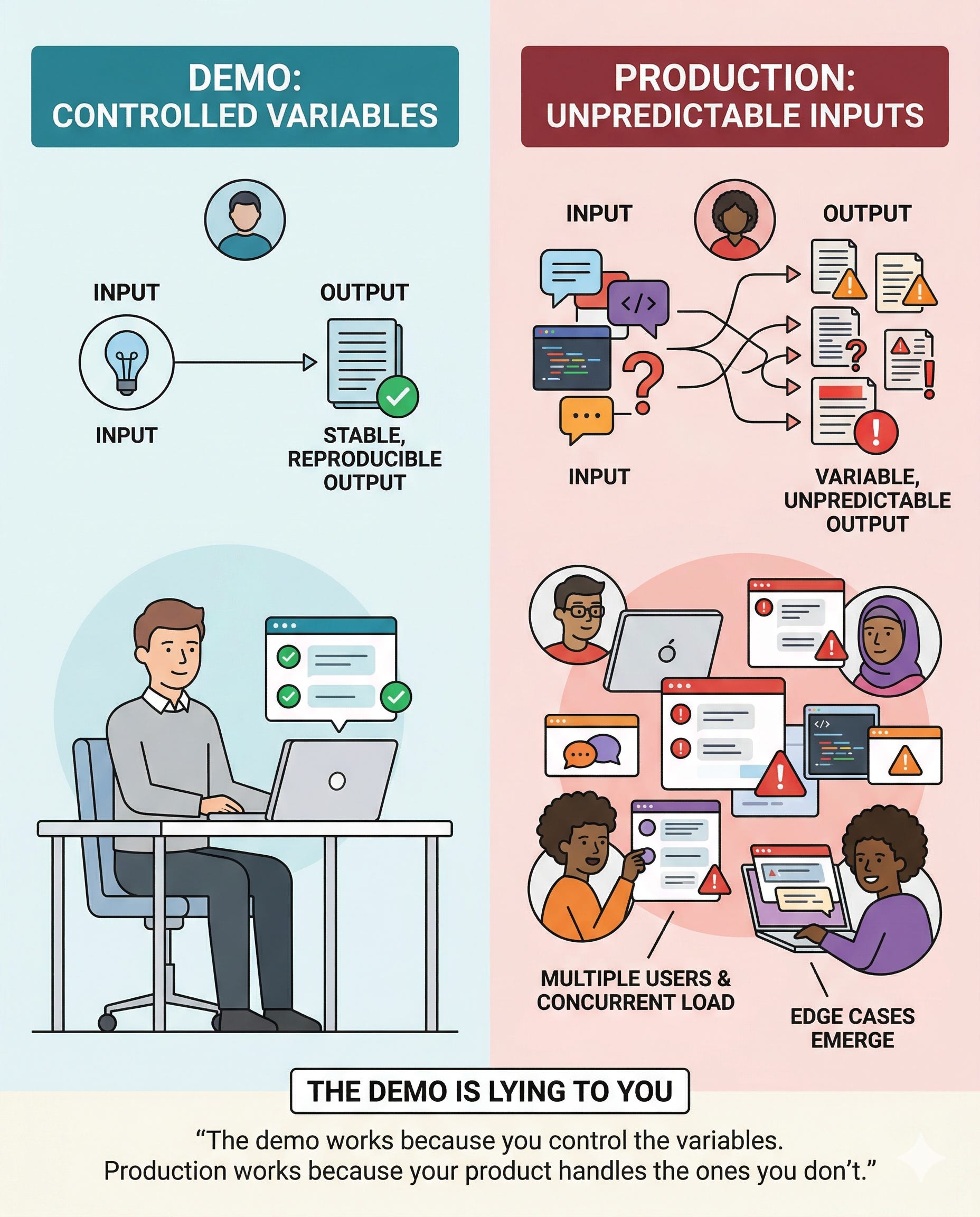
The Demo Is Lying to You
Here’s the fundamental difference that most people underestimate: traditional software is deterministic. Given the same input, it produces the same output. Bugs are reproducible, testable, fixable.
LLMs are probabilistic by design. Given the same input, a language model might produce slightly different outputs. More importantly: given an input it hasn’t seen before — one outside the distribution your team tested — it might produce something completely wrong. Not wrong in a way that throws an error. Wrong in a way that looks right.
The demo works because you control the variables. Production breaks because your users bring the ones you don’t.
“The demo works because you control the variables. Production works because your product handles the ones you don’t.”
A support chatbot that handles 80% of cases correctly sounds like a win until you do the math: if you have 10,000 users, that's 2,000 broken experiences per day. Every 1% of failure that felt acceptable in testing becomes a business problem at scale.
And quality is only part of what the demo hides — production also surfaces latency under real load, cost per user at volume, infrastructure that needs to actually run, and monitoring that tells you something is wrong before the customer does.
The Architecture Mistakes You Make on Day One
I systems are inherently complex. The model itself is a black box. Its behavior is non-deterministic. Its outputs require interpretation. Its performance degrades in ways that aren’t immediately visible.
Given that complexity is unavoidable, adding unnecessary layers on top of it is a compounding mistake. The right principle for day one: simplicity is not a limitation, it’s a strategy. The simplest system that solves the problem is the correct starting point.
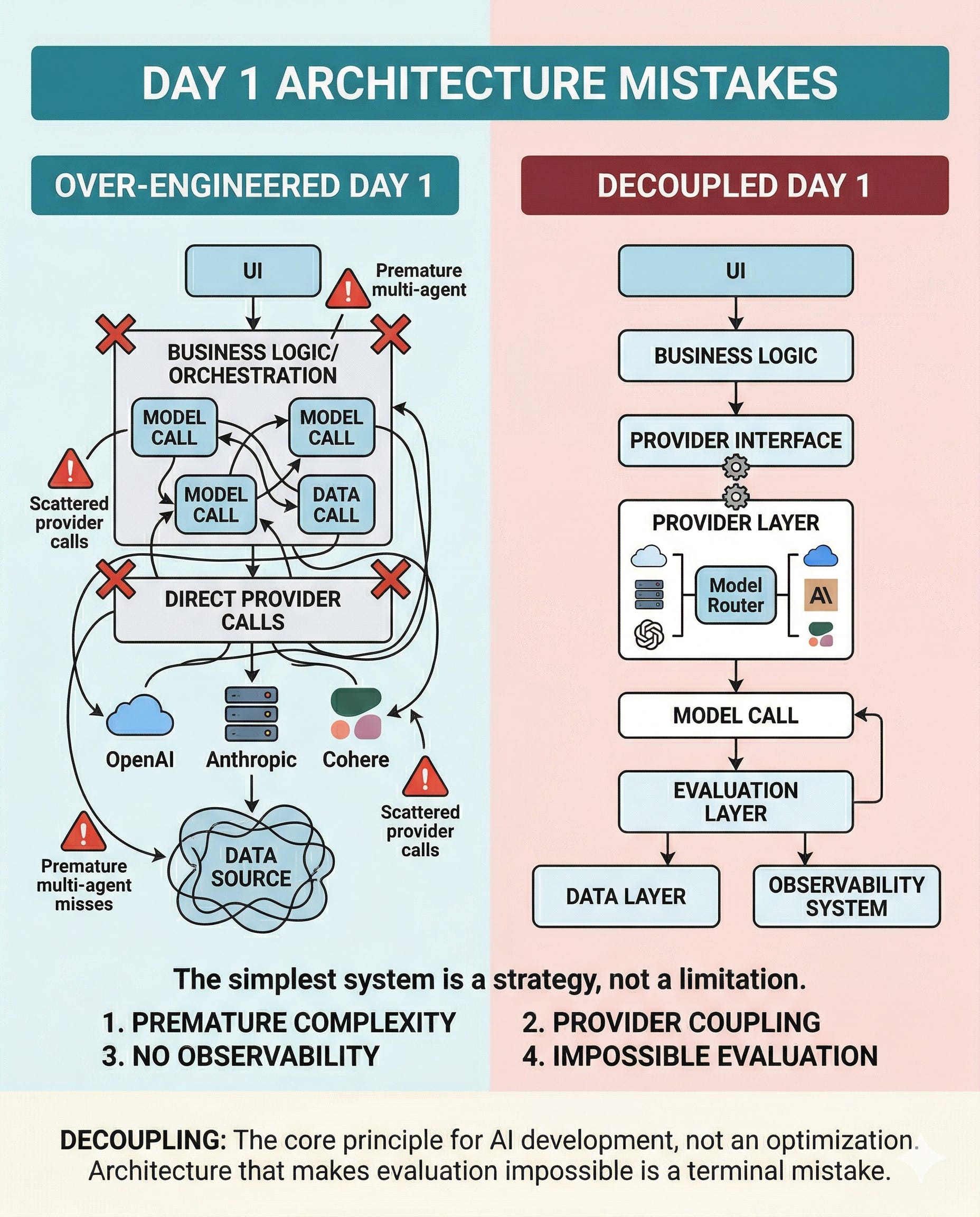
There are four architecture mistakes I see repeatedly in early-stage AI products:
Premature complexity. Teams reach for multi-agent setups, complex orchestration frameworks, and elaborate pipelines before they’ve validated what the product actually needs to do. The cost: three months building something no user will confirm works.
Provider coupling. When your application calls a model API directly in every place it needs to, you’ve created a dependency that’s expensive to change. Providers shift pricing. Models get deprecated. Better alternatives emerge. If migrating requires touching thirty files, you won’t migrate when you should.
Zero observability. Observability means having a live view of what your model is actually doing in production — what questions it’s receiving, what it’s answering, and where it’s failing. Without it, you’re flying blind. You’ll discover the product is broken when a customer tells you, not before.
Architecture that makes evaluation impossible. This one is subtle: if your system is structured so that you can’t isolate and test the model’s behavior independently, you’ve made it structurally impossible to know whether a change improved or degraded the product.
The thread connecting all four is decoupling — your provider, your data layer, your business logic, and your evaluation system should be independent from the start. Not as a refactor you’ll do later. As a design principle before line one.
In practice, provider coupling and zero observability are the ones that cost early-stage teams the most — and they’re also the easiest to address from day one, before the architecture becomes too expensive to change.
A useful question to bring to your next engineering meeting: if our main AI provider doubled its pricing tomorrow, how long would a migration take — and how many parts of the product would we need to rewrite? If nobody can answer that in under two minutes, you have a coupling problem.
The Mental Model That Changes Everything
Before picking a model, choosing a framework, or writing a prompt — there’s a more fundamental question: what position are you taking relative to AI in your product?
There are three positions a founder can assume.
AI as a feature. You have an existing product and you’re adding AI to improve it. A “summarize with AI” button on a document tool. An intelligent filter on a search interface. The product exists without AI — AI makes it incrementally better. This is a defensible position, but a limited one.
AI as the product. The pitch is “we use AI to do X.” There’s no value proposition beyond the technology itself. This is the wrapper problem — and it’s a trap. When the provider ships the same capability natively, your product disappears. “It’s GPT-4 for legal documents” is a feature waiting to be absorbed, not a business.
AI as a layer. The product solves a real problem. AI is the mechanism that delivers the solution — but the value is in the problem solved, not in the technology. Cursor isn’t “an editor with AI.” It’s a fundamentally different way to write software. The AI is what makes it possible, not what you’re selling.
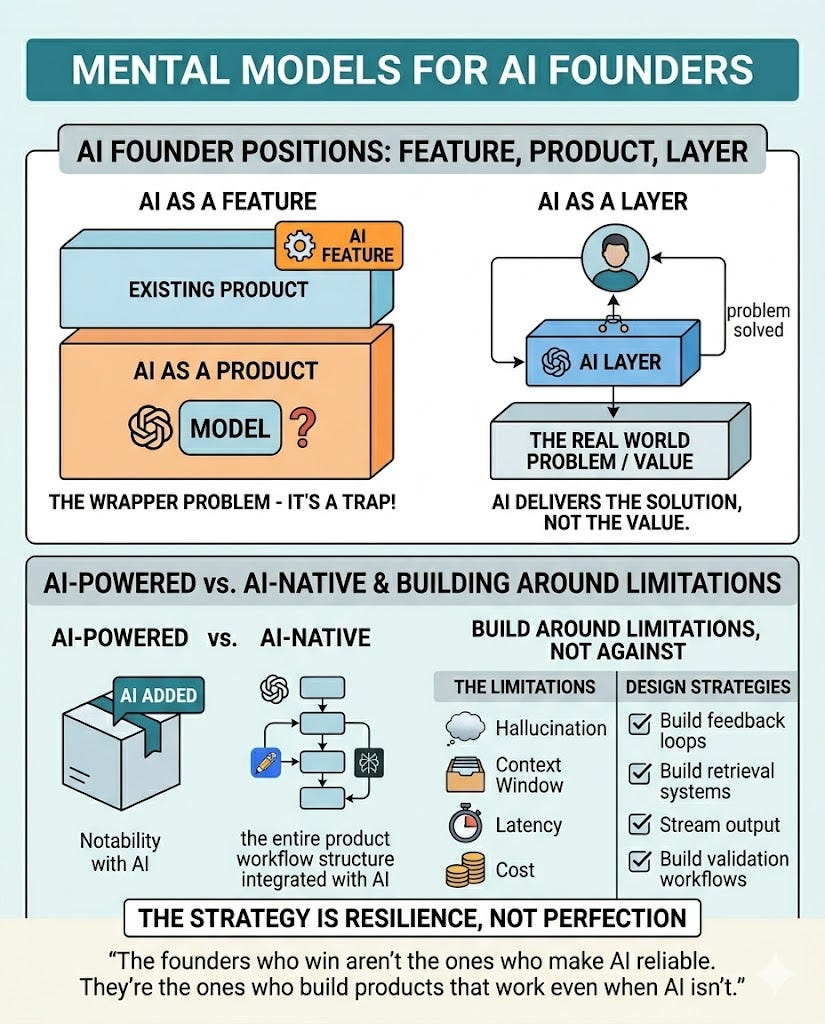
The other distinction worth internalizing: AI-powered versus AI-native. A powered product was built without AI and then AI was added — the workflow is the same as before, just faster or smarter. A native product was conceived assuming AI exists. You couldn’t remove the AI and still have something worth using. Notion AI is powered. Perplexity is native. Abridge — a tool that listens to doctor-patient conversations and generates clinical notes automatically — is native. The workflow it enables didn’t exist before AI made it possible. The distinction matters because native products can create new behaviors — things users couldn’t do before, not just things they can do faster. That’s where new habits form. That’s where defensibility lives.
Finally: build around the model’s limitations, not against them. LLMs hallucinate. They have finite context windows. They’re slow relative to traditional code. They cost money per token. Founders who try to eliminate these limitations lose — the constraint becomes the thing they’re always fighting. Founders who design around them win. Instead of chasing zero hallucination, design feedback loops that catch and correct errors. Instead of fitting everything into context, build retrieval that surfaces only what’s needed. Instead of making users wait, stream output so the product feels instant.
Before writing any code, five questions worth having clear answers to:
What is the exact task the model will perform — specific enough that you could evaluate it?
How will you know if the model did it well — what’s the measurable criterion?
What happens when the model is wrong — fallback behavior, consequence for the user?
What does it cost per use, and what will users pay — even a rough model?
Does a non-AI solution solve 80% of the problem — and if yes, why aren’t you starting there?

The trap isn’t the technology. It’s the assumption that a working demo means a working product — and that the gap between the two is primarily a technical problem.
It isn’t. It’s a product problem, an architecture problem, and a mental model problem. Get those right first, and the technical work becomes tractable.
Everything else in this series builds on that foundation.
This is Chapter 1 of AI Engineering for Founders — a series on building AI products that actually work in production. New chapters publish weekly.