
The AI Stack Trap
Every week there’s a new framework, a new model, a new tool that promises to change how you build AI products. The ecosystem moves fast — faster than most teams can track — and the instinct is to stay current, to evaluate everything, to make sure you’re not building on the wrong foundation.
That instinct is expensive.
The decisions you make about your AI stack in the first few months will either give you room to move quickly or create friction that compounds over time. Most founders I’ve talked to discover which one they chose about six months too late.
Here’s how to think about it from the start.
The map that actually matters
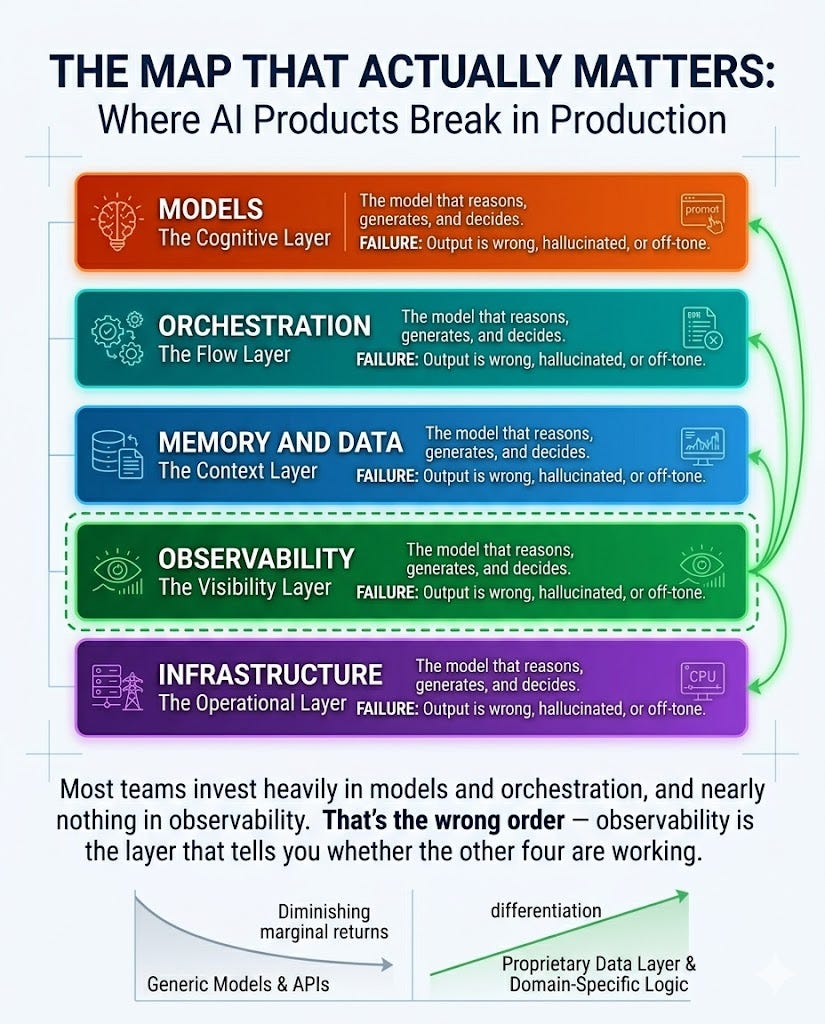
When an AI product breaks in production, it breaks in one of five places. That’s the frame worth using — not “what are all the tools in the ecosystem,” but “where does failure live, and what do I need to understand about each layer?”
The five layers:
Models — the cognitive layer. This is the LLM itself: the model that reasons, generates, and decides. When this layer fails, the output is wrong, hallucinated, or off-tone.
Orchestration — the flow layer. This is how your application coordinates model calls, routes inputs, chains steps, and manages what happens when something goes wrong. When this layer fails, the right thing happens at the wrong time, or in the wrong order, or not at all.
Memory and data — the context layer. This is everything your model knows beyond its training: your documents, your database, your users’ history. When this layer fails, the model answers with incomplete or outdated information — and sounds confident doing it.
Observability — the visibility layer. This is your ability to see what’s happening inside the system while it runs: what inputs the model receives, what it returns, where it hesitates, where it fails. When this layer is missing, you don’t have a visibility problem — you have a blindness problem.
Infrastructure — the operational layer. This is deployment, scaling, cost management, latency optimization, uptime. When this layer fails, the product works correctly and nobody can use it.
Most early-stage teams invest heavily in models and orchestration, and nearly nothing in observability. That’s the wrong order. Observability is the layer that tells you whether the other four are working.
“Most teams invest heavily in models and orchestration, and nearly nothing in observability. That’s the wrong order — observability is the layer that tells you whether the other four are working.”
The practical question worth asking your engineering team: in which of these five layers are we most exposed to a problem I wouldn’t be able to diagnose on my own? If nobody can answer that quickly, you have a gap.
What’s commoditizing fast: models and basic APIs. The gap between the best commercial models is narrowing every quarter. What still creates real differentiation: the data layer (what your product knows that nobody else’s does) and domain-specific orchestration (the logic that makes your product work for your specific use case).
Build vs. buy — the question behind the question
LangChain, LlamaIndex, CrewAI, LangGraph — libraries that wire together the different parts of an AI system: model calls, prompt formatting, context management, retry logic. They exist to help teams build AI products faster. And they do, under the right conditions.
The problem is that they also abstract exactly what you need to understand when things go wrong.
When a framework handles the orchestration between your model calls, the prompt formatting, the retry logic, and the context management — and something produces an unexpected output — you’re debugging at one layer of abstraction above the actual problem. That’s manageable when you understand what the framework is doing. It’s very expensive when you don’t.
“If you can’t explain what the framework does in two sentences, you shouldn’t depend on it in production.”
The honest version of build vs. buy isn’t a permanent decision. It’s a situational one:
Use frameworks when you’re building a proof of concept, when the functionality is well-defined and unlikely to need deep customization, or when your team is small and moving fast matters more than understanding every layer. A framework for a quick RAG prototype is fine. That same framework as the backbone of a production system you’ll need to debug and optimize for two years is a different bet.
Avoid frameworks — or plan to move past them — when you’re hitting behavior you can’t explain, when a breaking change has already cost you a sprint, when the framework’s abstraction is hiding the specific model behavior you need to tune.
The hidden cost of framework dependency isn’t the framework itself. It’s what happens to your team’s ability to reason about the system over time. When your engineers stop understanding what’s actually happening between the user’s input and the model’s output, iteration slows down. Debugging becomes archaeology. And when you need to migrate — to a better model, a cheaper provider, a different architecture — the cost is measured in weeks, not days.
A useful question for your next engineering conversation: which parts of our product depend on third-party AI frameworks — and what would happen if those frameworks stopped being maintained? The answer will tell you how much optionality you’ve retained.
The model decision
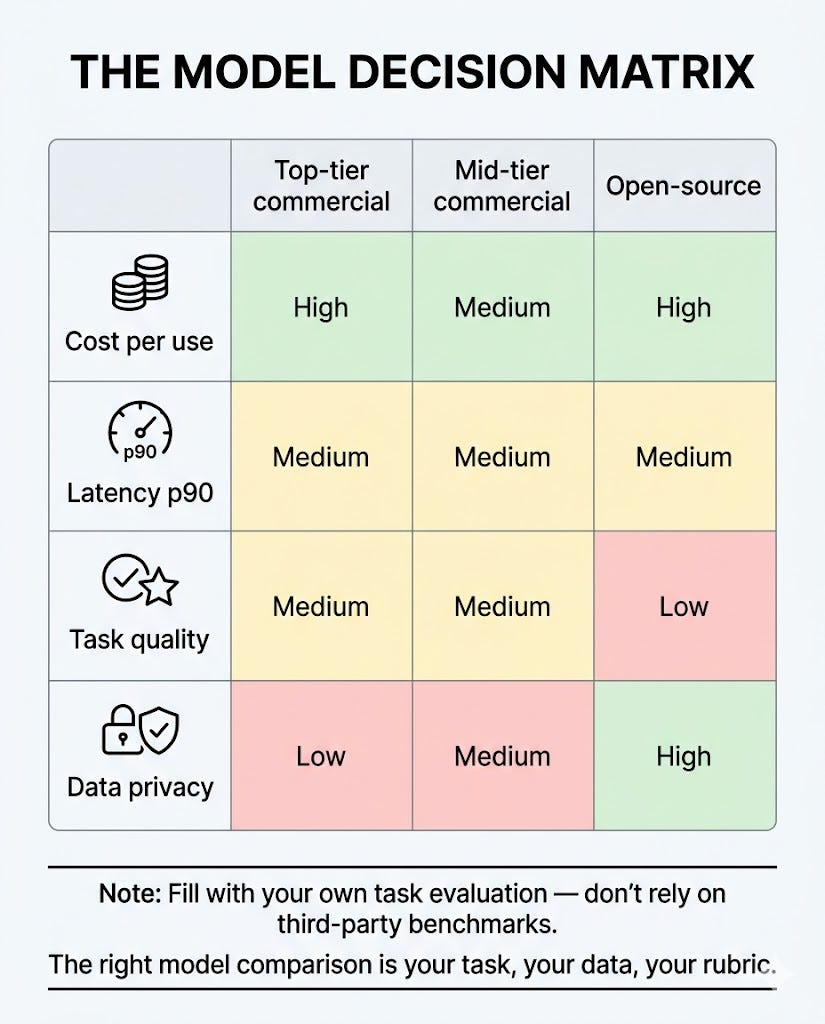
The most common mistake founders make when choosing a model: comparing benchmarks.
Benchmarks measure performance on standardized tasks designed to test general capability. Your product has a specific task, specific data, and specific criteria for what “good” looks like. Those three things are almost never what the benchmark measured.
The right comparison is your task, your data, your rubric. Run the candidates against it. The model that wins on your evaluation is the right model — regardless of where it sits on a leaderboard.
The four variables that actually matter for a founder making this decision:
Cost per use. Not the published price per million tokens, but what it costs to complete your product’s actual task end-to-end — including all the context you send, all the output you receive, and any retries. This is the number that determines your margin.
Latency — the 90th percentile, not the average. The average response time looks good on a dashboard. What matters is what your slowest users experience in a bad moment — that’s the 90th percentile, or p90. If your p90 is painful, 10% of your interactions are broken, regardless of what the average says.
Quality on your specific task. This is the only one you can measure with your own evaluation set. It’s also the only one that actually matters for your product.
Data privacy. What happens to the inputs you send? Are they used for training? Are they stored? For products handling sensitive client data — legal, medical, financial — this isn’t a detail. It’s a requirement.
On multi-model routing: the idea is to use a cheaper, faster model for simple tasks and reserve the more capable (more expensive) model for the interactions that need it. A common pattern: use a lighter model to classify the user’s intent or extract structure from input, then route only the complex reasoning tasks to the more capable model. On products with varied task complexity, the cost reduction can reach 60–80%. This is worth designing for from the start — not as an optimization you’ll add later, because adding it later means touching architecture that’s already in production.
“The right model comparison isn’t a benchmark. It’s your task, your data, your rubric. The model that wins on your evaluation is the right model — regardless of where it sits on a leaderboard.”
My direct take: for most early-stage founders, start with a leading commercial model and measure before you optimize. Open-source models have real advantages at scale, but running them in production has operational costs (hosting, fine-tuning, maintenance) that almost no early-stage team should be absorbing before they’ve validated the product. The cost savings aren’t worth the distraction.
This applies across verticals. A legal tech startup evaluating models for contract analysis, a healthtech product summarizing clinical notes, a fintech tool parsing transaction descriptions — the decision process is identical: define your task precisely, build a small evaluation set with your real data, run the candidates, pick the winner. The leaderboard is irrelevant. Your use case isn’t.
Optimize later. Validate first.
The question worth putting to your engineering team: how did we evaluate the model we chose — and when did we last check whether it’s still the best fit for our use case? Model capabilities change every few months. The answer from six months ago may not be the right answer today.
These are the decisions that look small when you make them and feel enormous six months later. Not because any individual choice is irreversible — most aren’t — but because bad choices compound. A framework you don’t understand, a model you haven’t actually tested, a layer you’ve never instrumented: each one is manageable on its own. Together, they create a product that’s hard to improve and expensive to change.
The founders who get this right don’t make better decisions from the start. They make decisions they can revisit cheaply.
Chapter 2 of AI Engineering for Founders — The AI Stack Trap. New chapters weekly.